

HNSW indexes
HNSW is an algorithm for approximate nearest neighbor search. It is a frequently used index type that can improve performance when querying highly-dimensional vectors, like those representing embeddings.
Usage#
The way you create an HNSW index depends on the distance operator you are using. pgvector includes 3 distance operators:
| Operator | Description | Operator class |
|---|---|---|
<-> | Euclidean distance | vector_l2_ops |
<#> | negative inner product | vector_ip_ops |
<=> | cosine distance | vector_cosine_ops |
Use the following SQL commands to create an HNSW index for the operator(s) used in your queries.
Euclidean L2 distance (vector_l2_ops)#
Inner product (vector_ip_ops)#
Cosine distance (vector_cosine_ops)#
Currently vectors with up to 2,000 dimensions can be indexed.
How does HNSW work?#
HNSW uses proximity graphs (graphs connecting nodes based on distance between them) to approximate nearest-neighbor search. To understand HNSW, we can break it down into 2 parts:
- Hierarchical (H): The algorithm operates over multiple layers
- Navigable Small World (NSW): Each vector is a node within a graph and is connected to several other nodes
Hierarchical#
The hierarchical aspect of HNSW builds off of the idea of skip lists.
Skip lists are multi-layer linked lists. The bottom layer is a regular linked list connecting an ordered sequence of elements. Each new layer above removes some elements from the underlying layer (based on a fixed probability), producing a sparser subsequence that “skips” over elements.
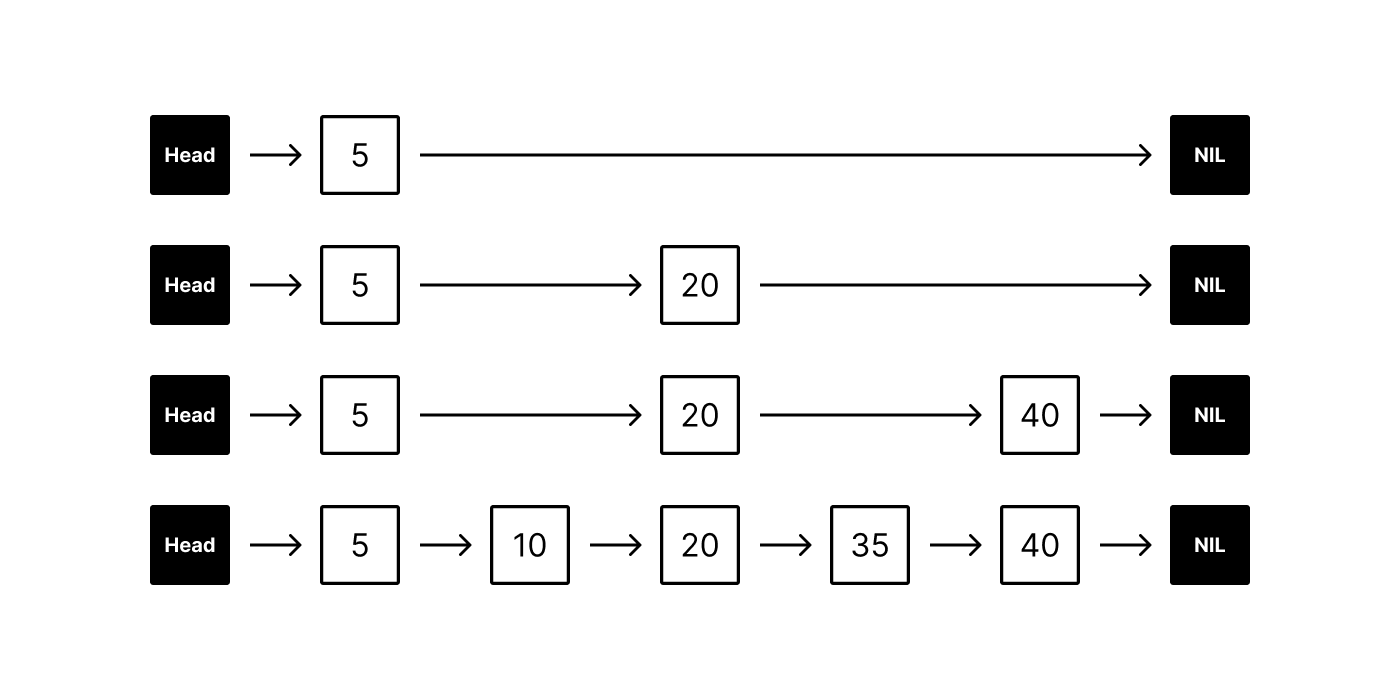
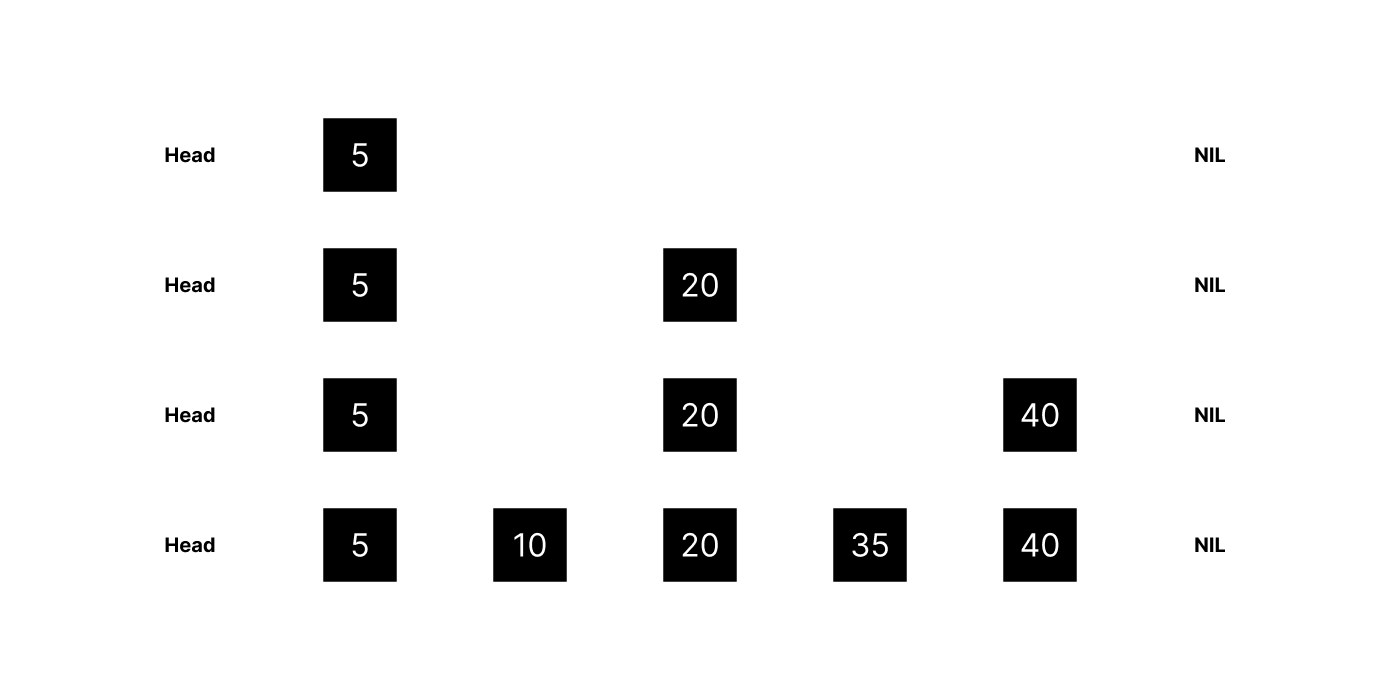
When searching for an element, the algorithm begins at the top layer and traverses its linked list horizontally. If the target element is found, the algorithm stops and returns it. Otherwise if the next element in the list is greater than the target (or NULL), the algorithm drops down to the next layer below. Since each layer below is less sparse than the layer above (with the bottom layer connecting all elements), the target will eventually be found. Skip lists offer O(log n) average complexity for both search and insertion/deletion.
Navigable Small World#
A navigable small world (NSW) is a special type of proximity graph that also includes long-range connections between nodes. These long-range connections support the “small world” property of the graph, meaning almost every node can be reached from any other node within a few hops. Without these additional long-range connections, many hops would be required to reach a far-away node.
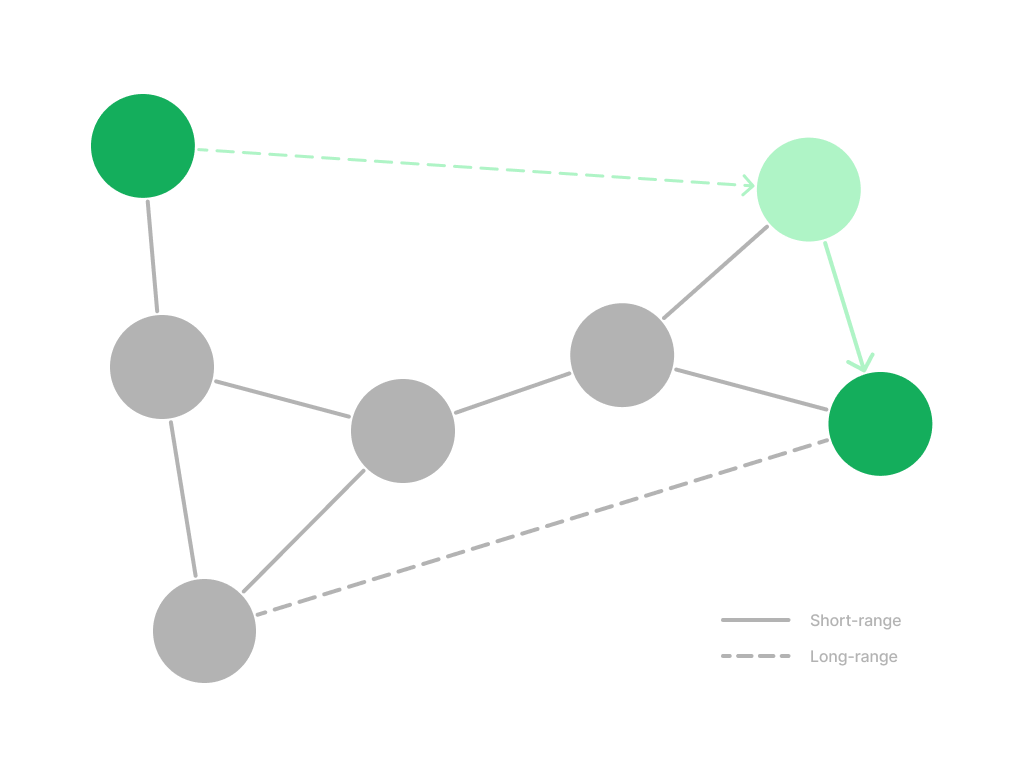
The “navigable” part of NSW specifically refers to the ability to logarithmically scale the greedy search algorithm on the graph, an algorithm that attempts to make only the locally optimal choice at each hop. Without this property, the graph may still be considered a small world with short paths between far-away nodes, but the greedy algorithm tends to miss them. Greedy search is ideal for NSW because it is quick to navigate and has low computational costs.
Hierarchical + Navigable Small World#
HNSW combines these two concepts. From the hierarchical perspective, the bottom layer consists of a NSW made up of short links between nodes. Each layer above “skips” elements and creates longer links between nodes further away from each other.
Just like skip lists, search starts at the top layer and works its way down until it finds the target element. However, instead of comparing a scalar value at each layer to determine whether or not to descend to the layer below, a multi-dimensional distance measure (such as Euclidean distance) is used.
When should you create HNSW indexes?#
HNSW should be your default choice when creating a vector index. Add the index when you don't need 100% accuracy and are willing to trade a small amount of accuracy for a lot of throughput.
Unlike IVFFlat indexes, you are safe to build an HNSW index immediately after the table is created. HNSW indexes are based on graphs which inherently are not affected by the same limitations as IVFFlat. As new data is added to the table, the index will be filled automatically and the index structure will remain optimal.
Resources#
Read more about indexing on pgvector's GitHub page.